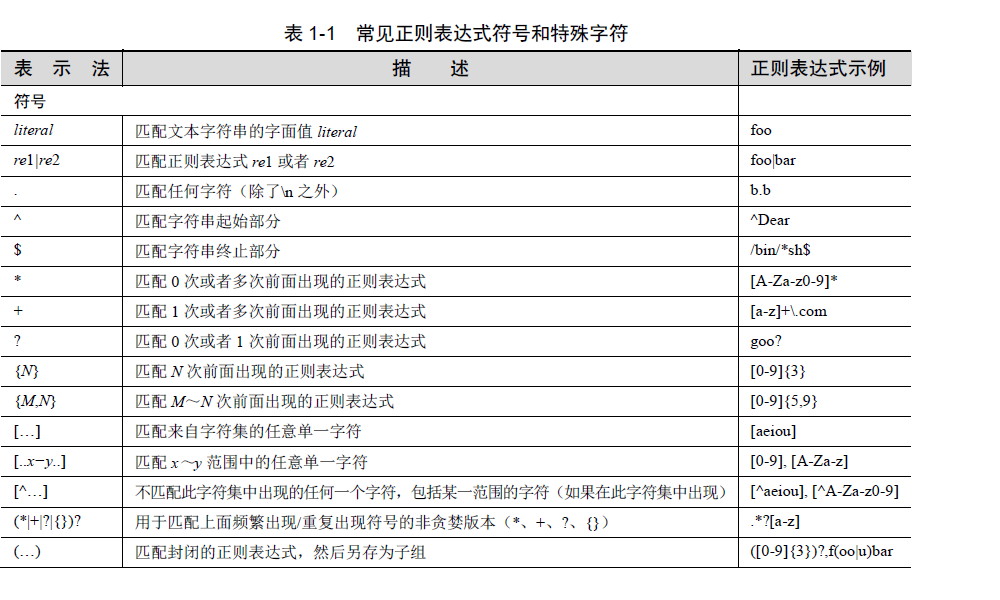
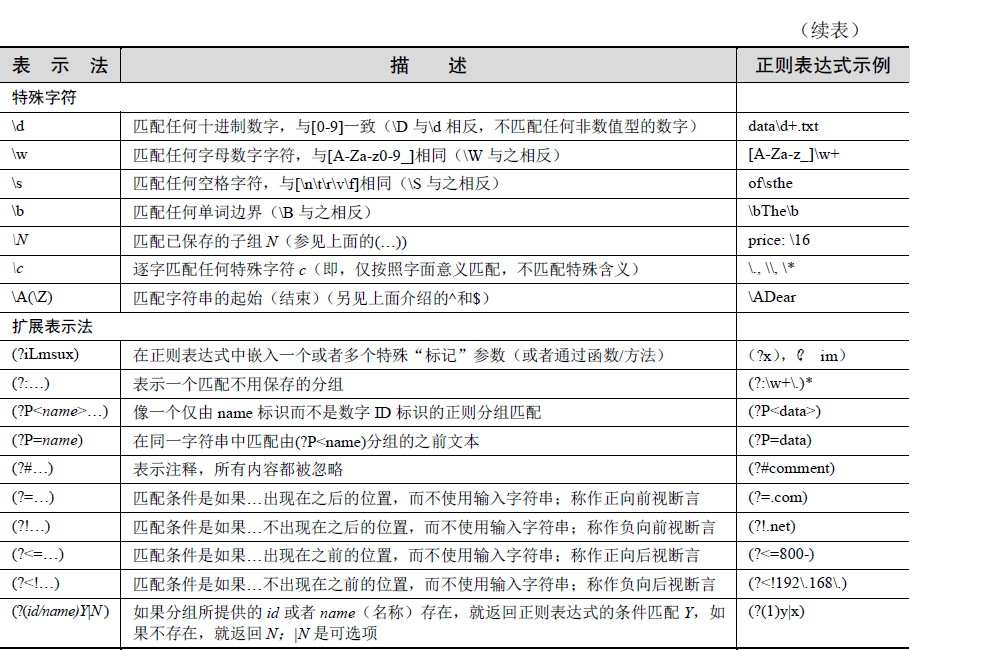
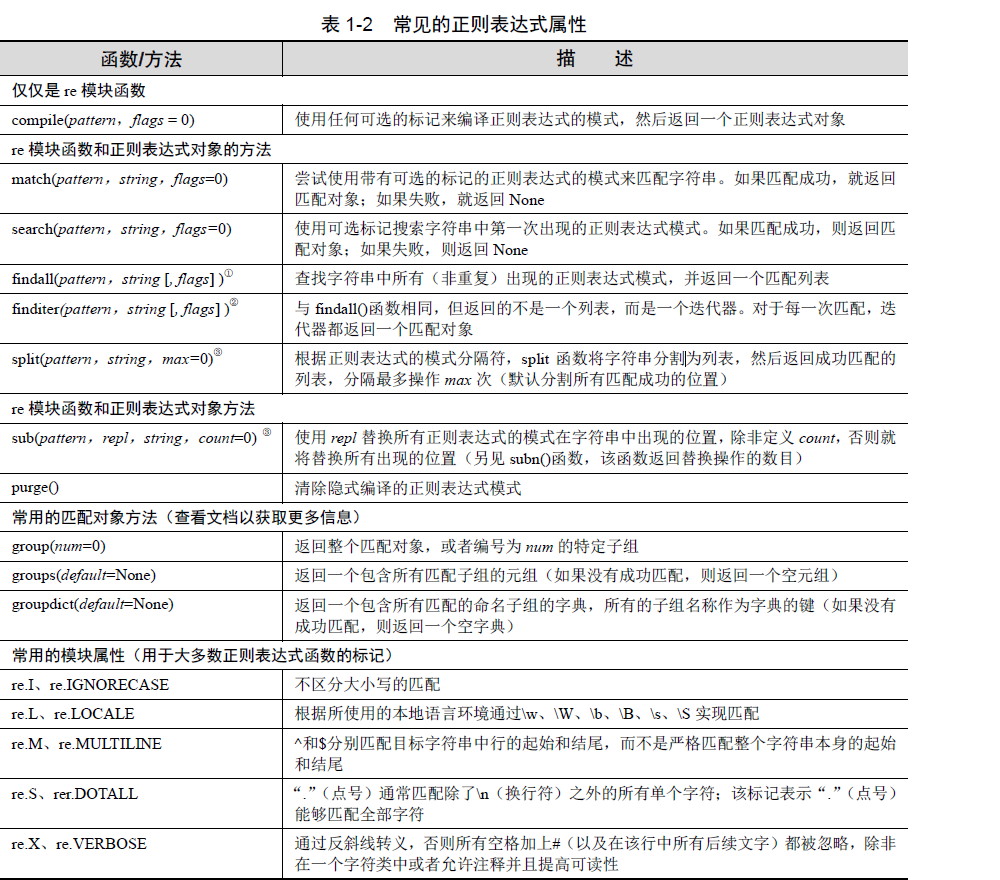
之前作过一版正则的,但是再看的时候看的很累,这次重新总结一下
match
import re
'''
match 是从对应的字符串开头匹配对应的内容,match不到则为None
'''
result = re.match('you', 'Young Frankenstein')
print(result) #None
source = 'Young Frankensteinn1n'
m = re.match('You', source)
print(m, type(m))#返回的是一个object
print(m.group(), type(m.group()))#匹配的结果
m = re.match('.*Frank', source) #这样返回到需求为止的所有字符串
if m:
print(m.group())
匹配多个字符串
下面这个代码的关注点在于我们是用 bt 去匹配后面的字符串,只要bt里面任意一个满足,就不为None
import re
bt = 'bat|bet|bit'
m = re.match(bt, 'bat')
n= re.match(bt, 'bet')
if m is not None:
if n is not None:
print(m.group(),n.group())
m = re.match('[cr][23][dp][o2]', 'c3po')# 匹配 'c3po' ,这样也可以
search search 也只是查询是否存在满足的条件,若存在多个数据,返回第一个结果 跟match唯一的区别就是不是从开头开始找
import re
a = "123abc456d"
print(re.search("([0-9]*)([a-z]*)([0-9]*)d",a).groups()) #groups 返回的是一个元祖,由除了group(0)之外的元素组成
print(re.search("([0-9]*)([a-z]*)([0-9]*d)",a).group(0)) #123abc456,返回整体,相当于group()
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
findall and finditer
import re
s = 'This and that and thid.'
a=re.findall(r'(th\w+) and (th\w+)', s, re.I) #re.I 是忽略大小写的意思,findall()总是返回一个列表
b=re.findall(r'(th\w+ and th\w+)', s, re.I) #re.I 是忽略大小写的意思,findall()总是返回一个列表
c=re.findall(r'(th\w+)', s, re.I)
print(a) #a[0]是tuple类型,因为查找内容为多个匹配
print(b) #b[0]是str类型,因为查找内容为1个匹配
print(c)
it = re.finditer(r'(th\w+)', s, re.I) #finditer相当于 iter(findall)
#对比 a和c可以发现,findall这边查找到第一个元素后,会在元素之后再进行查找,
# 简单来说,会缺失 “that and thid” 这种情况
# [('This', 'that')]
# ['This and that']
# ['This', 'that', 'thid']
使用正则进行字符串中的replace,split
import re
a=re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X,\n') #用'Mr. Smith'替换'X',返回str类型
b=re.subn('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')#用'Mr. Smith'替换'X',并计算替换次数,返回tuple类型
import re
DATA = (
'Mountain View, CA 94040 AS',
'Sunnyvale, CA',
'Los Altos, 94023',
'Cupertino 95014',
'Palo Alto CA',
)
for datum in DATA:
print(datum)
print(re.split(', |(?= (?:\d{5}|[A-Z]{2})) ', datum))